

Guilty. I'm indeed member of that part of society that might build up frustration because of traffic jams. Often do I wonder about ways of decreasing traffic jams in our little country, Belgium. One seemingly simple solution often comes to mind: just add more traffic lanes and all problems are gone, aren't they?
Why do I share this with you, you ask? During the last few years working as a data engineer with technologies as Apache Kafka and other streaming platforms, the following traffic jam metaphor crossed my path a number of times. Think of the cars being Kafka messages, the lanes Kafka consumers, and the road a Kafka topic. Adding new lanes to process more cars suddenly becomes more and more convenient.
In this post I will highlight the upsides of scaling Kafka consumers based on functional/application triggers, and showcase an implementation of functional triggers with KEDA, Kubernetes Event-driven Autoscaling.
Scaling Kafka consumers on Kubernetes
Let's start with implementing a plain dead simple Kafka consumer application in Python simulating a heavy process on top of incoming Kafka messages, or something similar: sleep for 60 seconds.
from kafka import KafkaConsumer
from datetime import datetime
import time
def print_now():
now = datetime.now();
current_time = now.strftime("%H:%M:%S")
print("Time = ", current_time)
consumer = KafkaConsumer('lazy-input-topic',group_id='lazy-consumer-group', bootstrap_servers='xyz:9092')
for msg in consumer:
print_now()
print (msg)
time.sleep(60)
Before deploying this as a Docker container on a Kubernetes cluster, we can run it locally and send some messages to the Kafka cluster. First create a topic with >1 partitions (important for the remainder of this post). Start the python consumer and watch it starting to consume messages.
./kafka-topics --create --topic lazy-input --partitions 10 --bootstrap-server xyz:9092
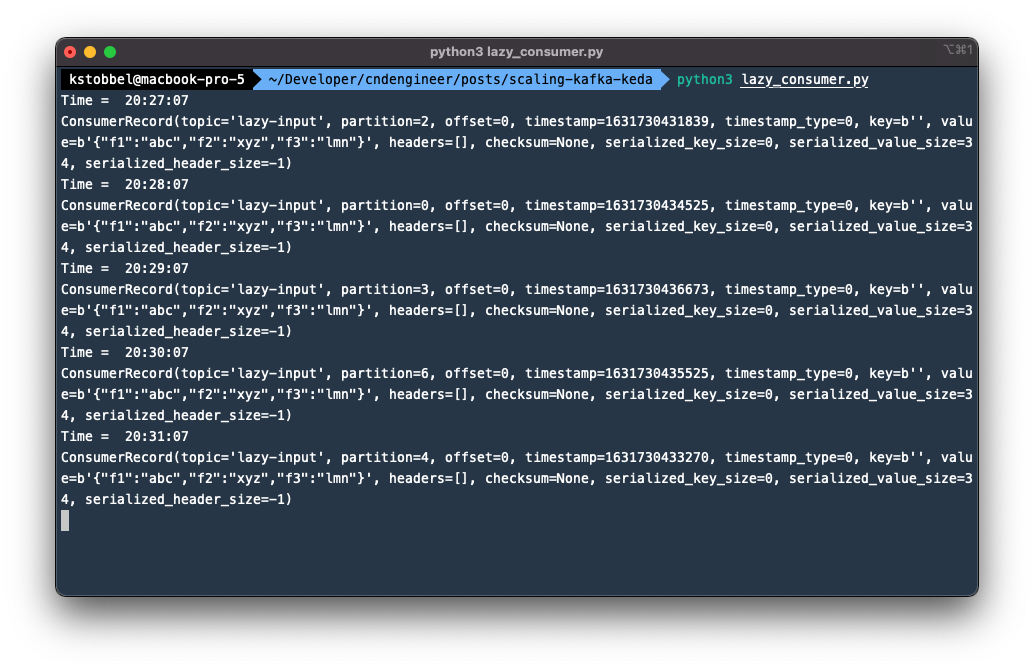
Great. All set to start scaling.
Getting started with KEDA, event-driven scaling for Kubernetes
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed.
Like most of the cloud native projects you can easily deploy KEDA on your own Kubernetes cluster with the help of their Helm chart.
Following commands will get you going:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda
KEDA is implemented following the Kubernetes Operator pattern. This means that upon installing KEDA your Kubernetes cluster gets extended with four Custom Resource Definitions (CRD): ScaledObjects, ScaledJobs, TriggerAuthentications, and ClusterTriggerAuthentications.
One more important thing to mention before we dive into it are the KEDA scalers. These are integrations based on which KEDA can decide to scale Kubernetes components. Obviously for this post we're interested in the Kafka integration, but the Azure Blob Storage scaler, for example, also seems worthy of some exploration time in the future!
Let's get going. We need to configure a ScaledObject. And apply it to our Kubernetes cluster.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: default
spec:
scaleTargetRef:
name: lazy-consumer
pollingInterval: 30
triggers:
- type: kafka
metadata:
bootstrapServers: kafka-kafka-bootstrap.default:9092
consumerGroup: lazy-consumer-group
topic: lazy-input
# Optional
lagThreshold: "50"
offsetResetPolicy: latest
kubectl apply -f scaled-object.yaml
One of the first things I noticed is that the existing deployment in which my lazy-consumer pod is running is scaled down to zero replicas by KEDA. This is confirmed by consulting the logs of the KEDA operator pod:
keda-operator 1.6476931939554265e+09 INFO scaleexecutor Successfully set ScaleTarget replicas count to ScaledObject minR │
│ eplicaCount {"scaledobject.Name": "kafka-scaledobject", "scaledObject.Namespace": "default", "scaleTarget.Name": "lazy-c │
│ onsumer", "Original Replicas Count": 1, "New Replicas Count": 0}
Now we can start publishing data onto our topic. I'm using Streamsets Datacollector for this, seeing I have an instance running on the same Kubernetes cluster. If you're following along just use whatever is the most efficient to get the job done.
And boom! Our consumer group is being scaled:
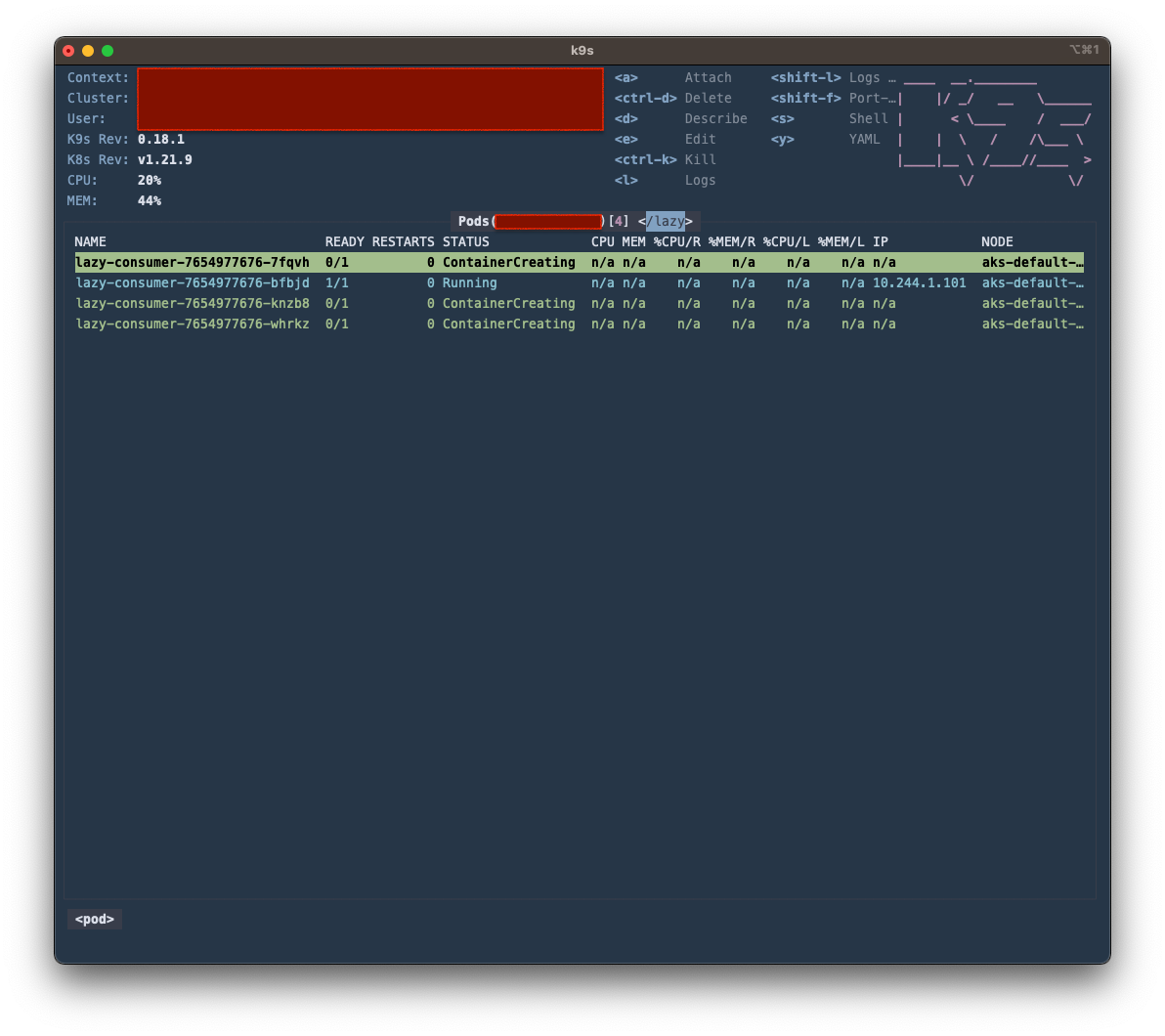
It takes some time for all consumers to actually start consuming messages (due to consumer group rebalances taking place) but they all start processing eventually. Once the consumer lag is gone, the deployment is scaled down.
But wait a minute, my deployment is not scaling down...
After some time, I started noticing weird things. It seems that the consumer pods are getting stuck in a neverending loop...
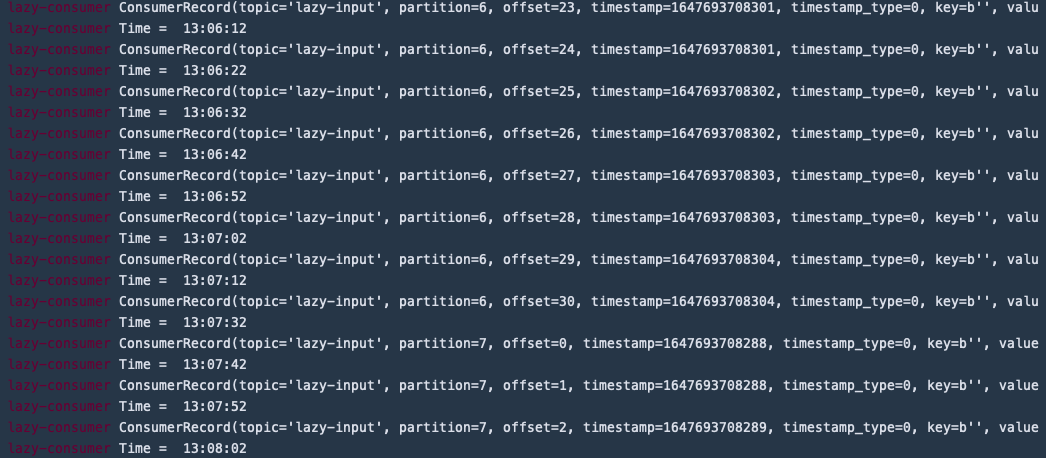
A few Github and Stackoverflow pages later, I learned that this is caused by the frequent rebalancing events happening on the consumer group. These rebalancing events are triggered due to KEDA continuously adding and removing new consumers to the group. These rebalancing events are sending the consumers back to the lastest commited offset which, in my case, is the initial offset.
Time to make a small change to our python script. I configured the KafkaConsumer to disable auto commiting offsets and added a manual commit after each message is processed. The final script:
from kafka import KafkaConsumer
from datetime import datetime
import time
def print_now():
now = datetime.now();
current_time = now.strftime("%H:%M:%S")
print("Time = ", current_time)
consumer = KafkaConsumer('lazy-input-topic',group_id='lazy-consumer-group', bootstrap_servers='xyz:9092', enable_auto_commit='False')
for msg in consumer:
print_now()
print (msg)
consumer.commit()
time.sleep(60)
Deploying these changes to the cluster and executing the experiment showed the results we expected before: the increased lag on the consumer group forces KEDA to scale up the deployment and once a consumer has done its job KEDA scales down the deployment, eventually to zero replicas. Nice.