

Knowing where your data lives, what it means and what it looks like is becoming more and more important. As data moves from system to system, or from data product to data product a clear and intuitive overview of your datasets across your application landscape lets others explore and wonder.
If you're like me, a tiny bit all over the place when excited, data discoverability might even help to bring some order in your home experiments with data. Lately I have been playing around with some data sets and when moving the data I'm most used to Apache Kafka to help me out. Once I get going the amount of Kafka topics quickly explodes. This had lead me into the lookout for a tool on top of Kafka to not only get an overview of the available Kafka topics - there's lots of tools out there for that, I for example frequently use Kafdrop - but also the corresponding metadata, e.g. the underlying schema, the definition(s), etc.
One of the tools that came up was DataHub from the engineering team at LinkedIn. "A Metadata Platform for the Modern Data Stack" is their slogan, and from my point of view this highlights the two critical pieces of the tool: first of all it consists of a user friendly UI in which the (meta)data can be explored and discovered, secondly it comes with a lot of integrations to modern data repositories and data wrangling tools out of the box. Luckily for this blog post, they do have an integration to Apache Kafka as well.
Deploy your own DataHub instance
Enough talking, on to the doing. The prerequisites: a running Kubernetes cluster and Helm ready to deliver. That's it. DataHub provides two Helm charts to get you up and running: one for the underlying components (Elastic Search, neo4j, Mysql, and the Confluent platform) and one for the DataHub components itself. Following commands should get you started:
helm repo add datahub https://helm.datahubproject.io/
helm install prerequisites datahub/datahub-prerequisites
helm install datahub datahub/datahub
If all goes well you can use Kubernetes port-forwarding to access your DataHub instance (initial credentials: "datahub:datahub"):
kubectl port-forward <datahub-frontend pod name> 9002:9002
Integrate existing Kafka metadata
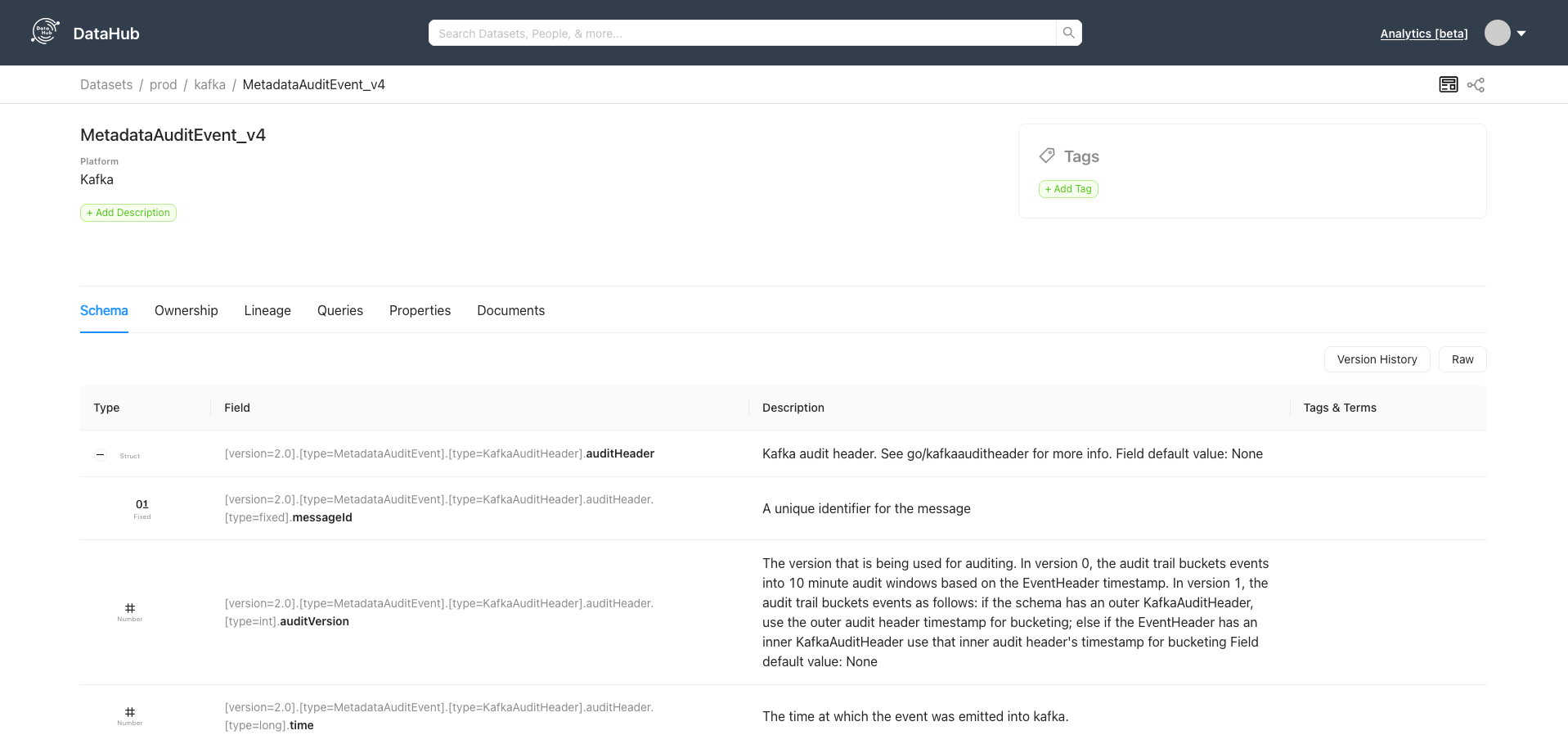
Once we've got DataHub up and running, next step on our data discoverability journey is to setup an integration between our Kafka cluster and DataHub. DataHub delivers an excellent job documenting their existing integrations, the Kafka Metadata ingestion is described on this page.
In order to make the Kafka metadata ingestion repeatable, I have combined the necessary statements in a Dockerfile.
FROM python:3.9
RUN python3 -m pip install --upgrade pip wheel setuptools \
&& python3 -m pip install --upgrade acryl-datahub \
&& pip install 'acryl-datahub[kafka,datahub-kafka]'
Next we need to create a recipe yaml file to configure the type of metadata ingestion we want to execute. Based on the DataHub documentation, it is quite easy to end up with this sample to load Kafka topics into DataHub:
source:
type: "kafka"
config:
connection:
bootstrap: "broker:9092"
schema_registry_url: "https://xyz:8081"
sink:
type: "datahub-kafka"
config:
connection:
bootstrap: "broker:9092"
schema_registry_url: "https://xyz:8081"
After building this Dockerfile, we can run the container locally and provide the recipe file holding the configuration properties for the ingestion of the Kafka topics to DataHub.
docker run --dit --name kafka-datahub-loader -v /<$PWD>/kafka-to-datahub-recipe.yml:/recipe.yml ./datahub ingest -c /recipe.yml
And tada: the existing Kafka topics are available in DataHub!
Repeat with Airflow
Once your project gets going and the amount of Kafka topics starts to grow, you may want to automatically ingest new Kafka metadata periodically. For this, one might consider Apache Airflow, a platform to manage workflows.
I deployed Airflow on my K8S cluster using their own Helm chart, which can be found here. I did tweak some parts of the configuration in the corresponding values file but leaving that out for this post. Or maybe, as you will see in the sample DAG implementation, the Airflow pods need access to the DataHub python package, the values file includes an option to define pip packages that are installed during deployment. Use that to install extra packages.
extraPipPackages:
- "acryl-datahub==0.8.11.1"
- "acryl-datahub[kafka]"
- "acryl-datahub[datahub-kafka]"
Once Airflow is up and running, all we need to do is implement a DAG that will execute the necessary steps to ingest the Kafka metadata into DataHub. Starting from an example exposed by DataHub, I came up with following DAG:
from datetime import timedelta
from airflow import DAG
try:
from airflow.operators.python import PythonOperator
except ModuleNotFoundError:
from airflow.operators.python_operator import PythonOperator
from airflow.utils.dates import days_ago
from datahub.configuration.config_loader import load_config_file
from datahub.ingestion.run.pipeline import Pipeline
from datetime import datetime
def datahub_recipe():
pipeline = Pipeline.create(
# This configuration is analogous to a recipe configuration.
{
"source": {
"type": "kafka",
"config": {
"connection": {
"bootstrap": "broker:9092",
"schema_registry_url": "http://xyz:8081",
},
},
},
"sink": {
"type": "datahub-kafka",
"config": {
"connection": {
"bootstrap": "broker:9092",
"schema_registry_url": "http://xyz:8081",
},
},
},
}
)
pipeline.run()
pipeline.raise_from_status()
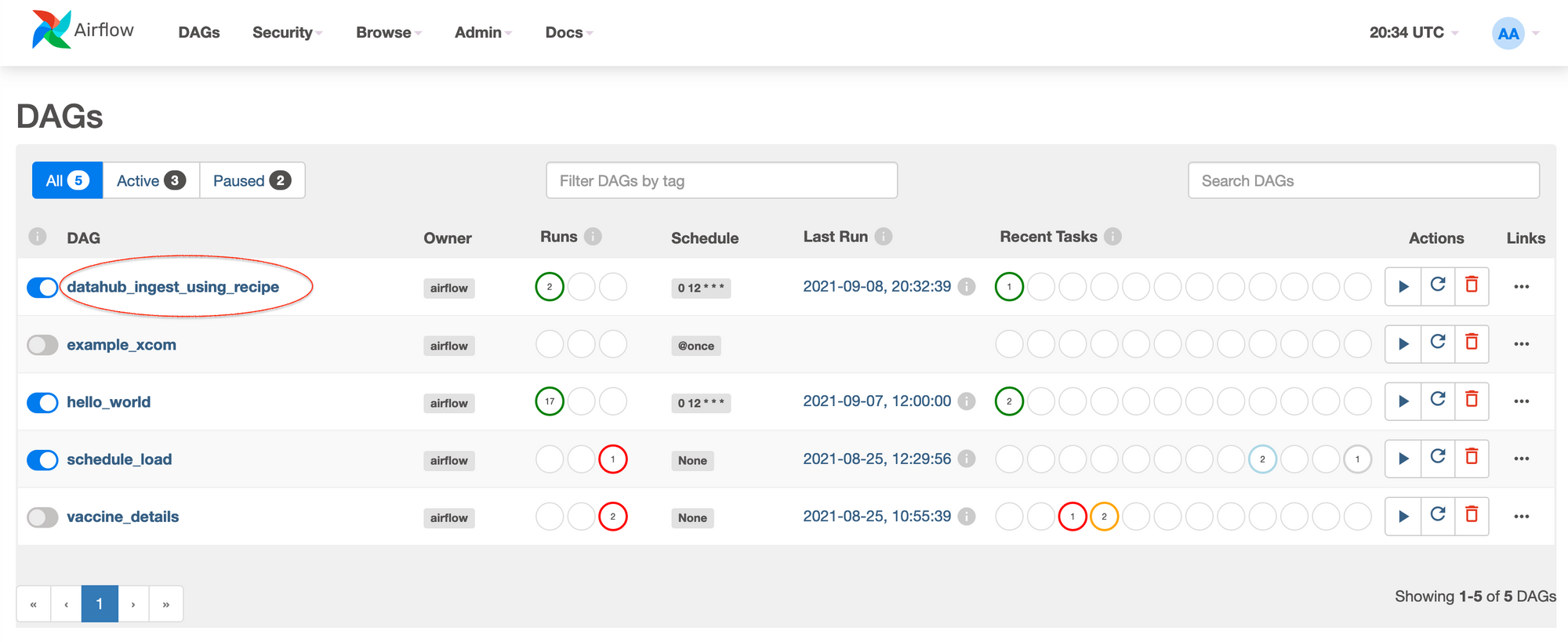
dag = DAG('datahub_ingest_using_recipe', description='Loading Kafka Metadata into DataHub', schedule_interval='0 12 * * *', start_date=datetime(2017, 3, 20), catchup=False)
datahub_operator = PythonOperator(task_id='ingest_using_recipe', python_callable=datahub_recipe, dag=dag)
datahub_operator
If all went well, after uploading the DAG into Airflow, you should be able to run the DAG to ingest new Kafka metadata into DataHub.
Alternatively you could schedule running the previously created Docker Image as a CronJob on your Kubernetes cluster.
Closing remarks

A few open questions/remarks I have after writing this post:
- if you're not using a predefined schema for your Kafka topics, there's not a lot of information to be found in DataHub other than a list of Kafka topics (although you might add extra metadata manually)
- still not sure if Airflow is the right tool for configuring the automatic ingestion of Kafka Metadata, it kinda felt like yet another tool do to something quite simple in K8S, but Airflow does give you an higher level of workflow management and monitoring...
- debugging Airflow was weary, untill I figured out I should start running the python code locally before uploading it to the Airflow instance running on K8S...