

Streaming MongoDB Oplog Records to Kafka
A few years ago I had to come up with a system to stream operational data to a Data Warehouse for (near) real time analytics. The operational data was living in a MongoDB. Part of the resulting architecture looked like this:
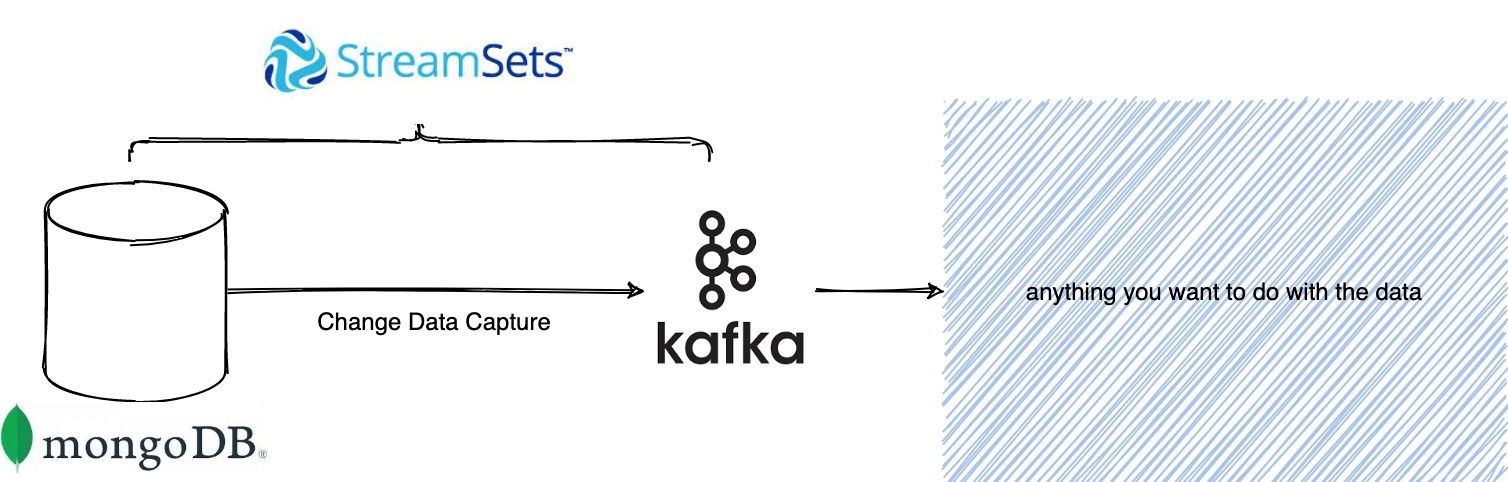
To have real time data we decided to apply Change Data Capture on top of the MongoDB. We stumbled upon Streamsets Datacollector to help us with this. It comes with an out of the box integration to capture MongoDB change events by processing the MongoDB oplog. The MongoDB oplog is a dedicated collection in the local database that keeps track of every operation taking place on a collection in the MongoDB instance. With the help of Streamsets it was child's play to publish the oplog records into a Kafka topic.
This all works fine, but working with oplog records has one main drawback. Let's take a look at an update operation and how this operation is reflected in an oplog record.
rs0:PRIMARY> db.product.updateOne( { id: "1234" }, { $set: { "size": "L", status: "P" }})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
rs0:PRIMARY> db.product.find()
{ "_id" : ObjectId("5e05d3573097942bf4e37a60")
, "id" : "1234", "label" : "dummy", "size" : "L", "status" : "P" }
-- In the oplog
{ "ts" : Timestamp(1577440106, 1)
, "t" : NumberLong(19)
, "h" : NumberLong("4817342222804408742")
, "v" : 2
, "op" : "u"
, "ns" : "company.product"
, "ui" : UUID("651f7a10-6eea-4b3b-9afe-178a5b7c297e")
, "o2" : { "_id" : ObjectId("5e05d3573097942bf4e37a60") }
, "wall" : ISODate("2022-03-20T09:48:26.279Z")
, "o" : { "$v" : 1
, "$set" : { "size" : "L", "status" : "P" } } }
The actual change is reflected in the "o" field of the oplog record. There's no indication of the full record before or after this operation. If we want to know the actual status of the full record we will need to merge this individual operation with the history of changes we captured for the same record. Certainly not unmanageable but supporting all the different ways of updating a record in MongoDB takes some time. And I'm still not talking about handling updates to nested documents...
Time to call Batman and Robin, or in this case Debezium and Kafka Connect
For another project I did some research into tools that are capable of performing change data capture on top of Oracle databases. When looking for a tool that didn't use Oracle's logminer process, I quickly got familiar with the Debezium project. The description on the top of the site is quite promising:
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
And even more favorable: they have a MongoDB connector! When taking a deep-dive into the documentation of the connector it seems that Debezium is not using the MongoDB oplog but another feature called the Change Streams. MongoDB is advertising to use this feature in stead of the oplog. By default these change streams only capture the actual change or the resulting delta of the operation. However you can configure it to return the full document reflected after the operation.
In the remainder of this post I will guide you through the setup of Debezium together with Kafka Connect to capture change events on top of MongoDB.
Hands-on implementation of Debezium and Kafka Connect
Before we really get started, there are some prerequisites:
- a working and accessible Kubernetes cluster
- the Strimzi Kafka Operator installed on the K8S cluster
- a MongoDB instance
I'm using the Strimzi Kafka Operator not only to easily deploy a Kafka Cluster, it also let's me configure Kafka Connect clusters and Kafka Connect connectors as CRD instances. And suprise, surprise, Kafka Connect happens to be one of the ways to setup Debezium.
We will need three things to setup a Debezium integration with the help of Kafka Connect: a Docker image for the Kafka Connect workers (1), a Kafka Connect Cluster specification (2), and a Kafka Connect Connector specification (3). The Kafka Connect Connector will hold the configuration of the Debezium integration with MongoDB.
1. A Dockerfile for the Kafka Connect worker Pods
The worker pods of the Kafka Connect cluster need access to the appropriate libraries to use Debezium and Debezium's MongoDB connector. For this, we can extend a Dockerfile, provided by Strimzi, with the source code of the plugin. Download the plugin from the Confluent pages and add it to a new directory "plugins". The resulting Dockerfile looks like this:
FROM strimzi/kafka:latest-kafka-2.6.0
COPY ./plugins/ /opt/kafka/plugins/
USER 1001
Build and push the resulting Docker image to the registry of your preference. I'm using my personal registry on Dockerhub.
2. A Kafka Connect Cluster Specification
Secondly we need to setup our Kafka Connect cluster. For this we can use the KafkaConnect CRD, imported via the Strimzi Kafka Operator. Most of the configuration is kept pretty default, make sure to replace the image reference to the Docker image you pushed in the previous step.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: kstobbel-connect-cluster
annotations:
strimzi.io/use-connector-resources: "true"
spec:
replicas: 3
image: kstobbel/kafka-connect-mongodb:1.0.1
bootstrapServers: kafka-kafka-bootstrap:9092
config:
group.id: kstobbel-connect-cluster
offset.storage.topic: kstobbel-connect-cluster-offsets
config.storage.topic: kstobbel-connect-cluster-configs
status.storage.topic: kstobbel-connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
logging:
type: inline
loggers:
log4j.rootLogger: "INFO"
After applying this yaml specification to the cluster, three new pods should be starting in the current namespace.

3. A Kafka Connect Connector Specification
Last but not least we need to configure our Debezium MongoDB connector. Again using the Strimzi Kafka operator, all we need to do is configure the Kafka Connector CRD:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: "cdc-connector"
namespace: default
labels:
strimzi.io/cluster: kstobbel-connect-cluster
spec:
class: io.debezium.connector.mongodb.MongoDbConnector
tasksMax: 1
config:
mongodb.hosts: mongodb-headless:27017
mongodb.name: products
snapshot.mode: never
collection.include.list: company.product
Credentials are left out on purpose.
Bringing it all together
We are ready to deploy our Debezium Connector, apply the manifest! Great. Once deployed, one of the Kafka Connect workers is instructed to setup the MongoDB integration. If we take a deeper look into the logs of this worker we see a lot of errors in the console:
kstobbel-connect-cluster-connect 2022-03-21 16:38:09,030
WARN [Producer clientId=connector-producer-cdc-connector-0]
Error while fetching metadata with correlation id 509 :
{products.company.product=UNKNOWN_TOPIC_OR_PARTITION}
(org.apache.kafka.clients.NetworkClient)
[kafka-producer-network-thread connector-producer-cdc-connector-0]
The worker pod seems to have issues with the Kafka topic. After manual creation of the Kafka topic (in our case "products.company.product") we should be fine. Shall we insert some dummy data in our MongoDB collection?
db.product.insertOne({"input": "abc12345"})
The payload part of the corresponding Kafka message looks like this (I'm leaving out the schema definition of the message):
{
"after": "{\"_id\": {\"$oid\": \"6238a9bd5a957ffd1073cac6\"},\"input\": \"abc123\"}",
"patch": null,
"filter": null,
"updateDescription": null,
"source": {
"version": "1.8.1.Final",
"connector": "mongodb",
"name": "products",
"ts_ms": 1647880637000,
"snapshot": "false",
"db": "company",
"sequence": null,
"rs": "rs0",
"collection": "product",
"ord": 1,
"h": null,
"tord": null,
"stxnid": null,
"lsid": null,
"txnNumber": null
},
"op": "c",
"ts_ms": 1647880637552,
"transaction": null
}
So far so good, the insert operation is captured by the Kafka Connector and looks familiar. Let's try an update operation.
db.product.updateMany({"input": "abc12345"}, {$set: {"input": "def456", "output": "changed"}})
The resulting Kafka message:
{
"after": "{\"_id\": {\"$oid\": \"6238a9fe5a957ffd1073cac7\"},\"input\": \"def456\",\"output\": \"changed\"}",
"patch": null,
"filter": null,
"updateDescription": {
"removedFields": null,
"updatedFields": "{\"input\": \"def456\", \"output\": \"changed\"}",
"truncatedArrays": null
},
"source": {
"version": "1.8.1.Final",
"connector": "mongodb",
"name": "products",
"ts_ms": 1647881865000,
"snapshot": "false",
"db": "company",
"sequence": null,
"rs": "rs0",
"collection": "product",
"ord": 1,
"h": null,
"tord": null,
"stxnid": null,
"lsid": null,
"txnNumber": null
},
"op": "u",
"ts_ms": 1647881865582,
"transaction": null
}
Cool! Not only does the message contain the update details, it also includes the state of the record after applying the operation. No more need to do manual merges to construct the full record body. True, we still need to parse the "after" field of the payload but I assume you can figure this out.
Final Remarks
To conclude this post I want to highlight a few things:
- Using the Strimzi operator brings a declarative approach to defining Kafka Connect integrations (in stead of performing some API calls)
- Having the "after" state of the record in the change event simplifies your data pipelines
- Replacing a Data Pipeline Orchestrator (like Streamsets Datacollector or Apache NiFi) by something like Kafka Connect might be limiting at first sight in terms of observability (what is happing with the connector)
- Might be something for one of the next posts!